

通过so-vits-svc实现AI歌曲翻唱,探索高效的声音克隆与转换技术。
直达下载
回到上一页 
介绍
so-vits-svc是一个集成了VITS模型和声音克隆技术的开源项目,专注于歌唱语音转换(SVC),而非传统的文本到语音(TTS)。这项技术以其在声音转换方面的高效表现而闻名,已成功应用于多个知名项目,如“AI孙燕姿”等。
核心功能
- 声音克隆:允许用户克隆自己的声音并转换其他音频至克隆声音。
- 高质量音频生成:即便是基本训练,也能生成合格的音质效果,对于追求更高质量的用户,通过增加训练步数(建议至少10,000步)可显著提升输出质量。
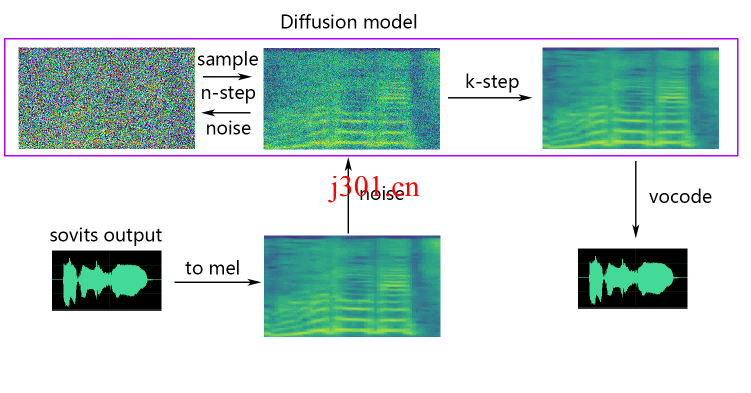
操作步骤详解
- 安装与环境准备
在开始前,需确保硬件条件符合需求,尤其是在使用GPU进行训练时。对于非Windows用户,建议在云平台如Colab进行操作以避免兼容性问题。 - 素材准备与处理
素材质量直接影响最终结果。理想的音频长度为30分钟以上,且需要是清晰的干声。如果背景音较多,可用“UVR5”软件进行干声提取。音频文件过长时,使用“Audio Slicer”工具进行切分,确保每段不超过15秒。 - 软件安装与数据准备
使用提供的链接下载so-vits-svc软件和必要的依赖库。准备好的数据集应按指定格式组织并存放在正确的目录下。 - 训练模型
在Colab或本地环境中运行所需的脚本开始训练。训练过程中,应密切关注loss值,这一指标反映了模型的训练质量。 - 模型推理与音频生成
训练完成后,即可使用模型进行声音转换,生成新的歌曲或声音文件。
我在Colab上运行so-vits-svc进行了尝试。虽然我只训练了800步,但已经可以感受到这个工具的强大功能。我上传了一段自己的声音,尽管结果不是完美的,但已经非常接近期待中的效果。如果想要更好的效果,我建议至少进行10,000步的训练。整个过程直观且富有教育意义,非常适合音频编辑和AI技术爱好者。
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“Github开源项目”或者“github1499” 或微信扫描右侧二维码关注微信公众号


 RSS
RSS
