


GPTCache:减少LLM API成本,提速缓存系统
GPTCache是一个强大的工具,适用于任何需要频繁使用LLM的应用程序。它不仅可以帮助开发者节省成本,还能通过提高响应速度和可扩展性,提升用户体验。
直达下载
回到上一页 
介绍
GPTCache是一个专门为大型语言模型(LLM)设计的缓存系统,旨在存储和管理LLM响应数据,从而减少API调用次数和成本。本文将详细介绍GPTCache的安装方法、主要功能和使用场景,帮助用户快速上手和有效利用这一工具。
安装GPTCache
首先,用户可以通过简单的pip命令安装GPTCache:
pip install gptcache
对于开发者和希望参与GPTCache开发的用户,可以克隆开发版仓库并安装:
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
pip install -r requirements.txt
python setup.py install
GPTCache的使用
GPTCache的使用非常直观。一旦安装完毕,您只需几行代码就能将其集成到现有的项目中。以下是一个简单的使用示例,展示了如何设置并初始化GPTCache:
from gptcache import cache
from gptcache.adapter import openai
cache.init()
cache.set_openai_key()
GPTCache的核心功能
- 成本效益:通过缓存查询结果,GPTCache显著减少了对LLM服务的请求次数,从而降低了费用。
- 性能提升:相比于直接请求LLM服务,GPTCache通过缓存相似的查询结果,显著提高了响应速度。
- 开发与测试环境适应性:GPTCache提供了一个仿真LLM API的接口,支持存储生成的或模拟的数据,便于开发者进行应用测试。
- 可扩展性和可用性:通过管理好的缓存系统,GPTCache支持应用的水平扩展,确保在用户基数增加时仍能保持良好的性能。
如何工作?
GPTCache通过语义缓存来优化性能,不仅匹配完全相同的查询,还能找到相似的请求。它利用嵌入算法将查询转换成嵌入向量,并在向量存储中进行相似性搜索,这大大提高了缓存命中率,从而提高了整体效率。
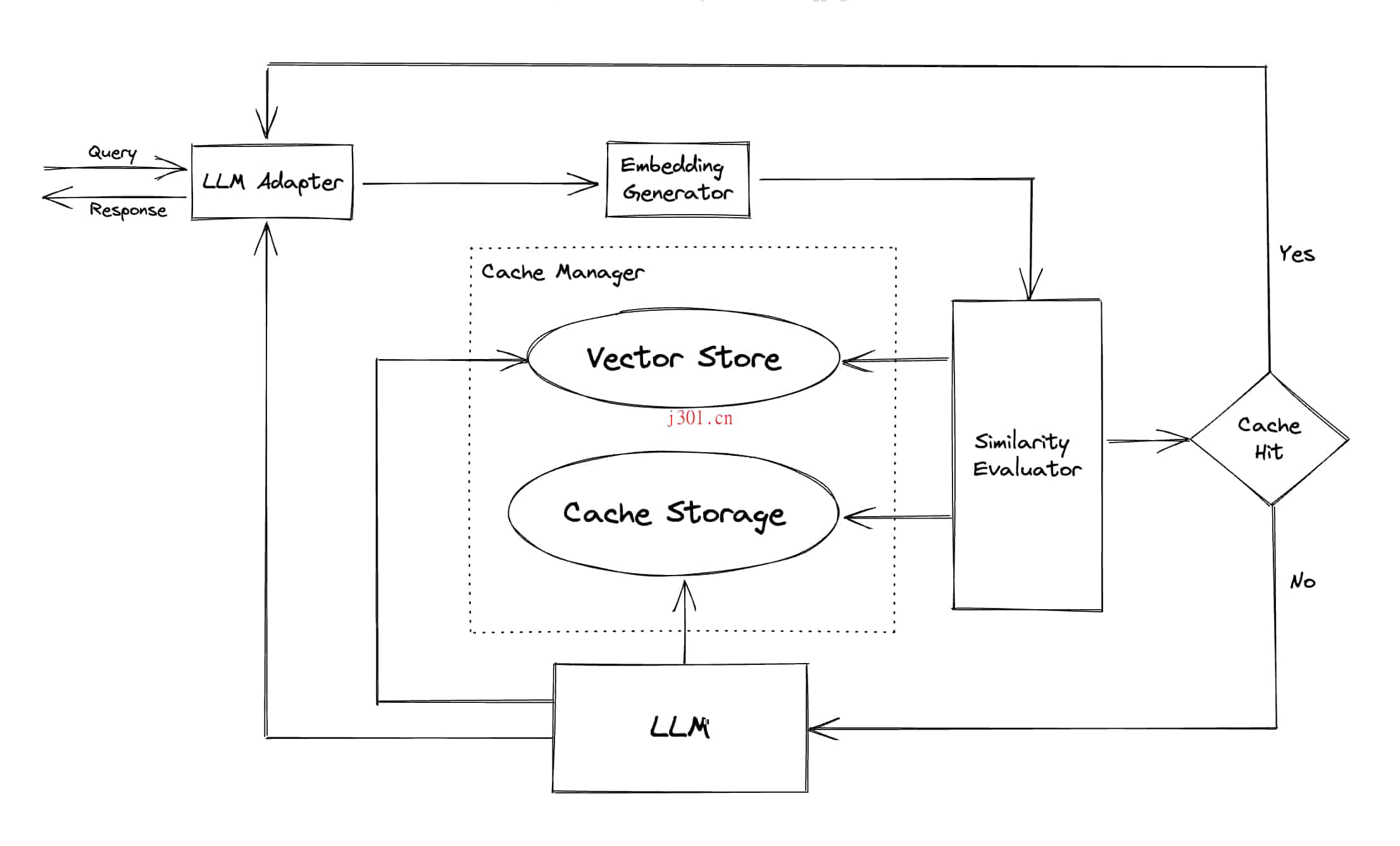
模块和架构
GPTCache具备模块化设计,包括LLM适配器、多模态适配器、嵌入生成器、缓存存储和向量存储等,每个模块都可以根据需要进行自定义或替换,以适应不同的使用场景和需求。
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序媛山楂”或者“shanzhacoder” 或微信扫描右侧二维码关注微信公众号
