


EMO(Emote Portrait Alive):生成会说话唱歌的 AI 视频

哇塞,阿里巴巴这次真是把AI玩到了新高度!他们最近推出的这款AI模型EMO,简直是把视频制作游戏化了。只要给它一张照片和一段音频,不管你想让照片中的人唱歌还是说话,EMO都能让这个人物“活”起来,嘴巴动起来,表情也跟着变,就像真的一样!
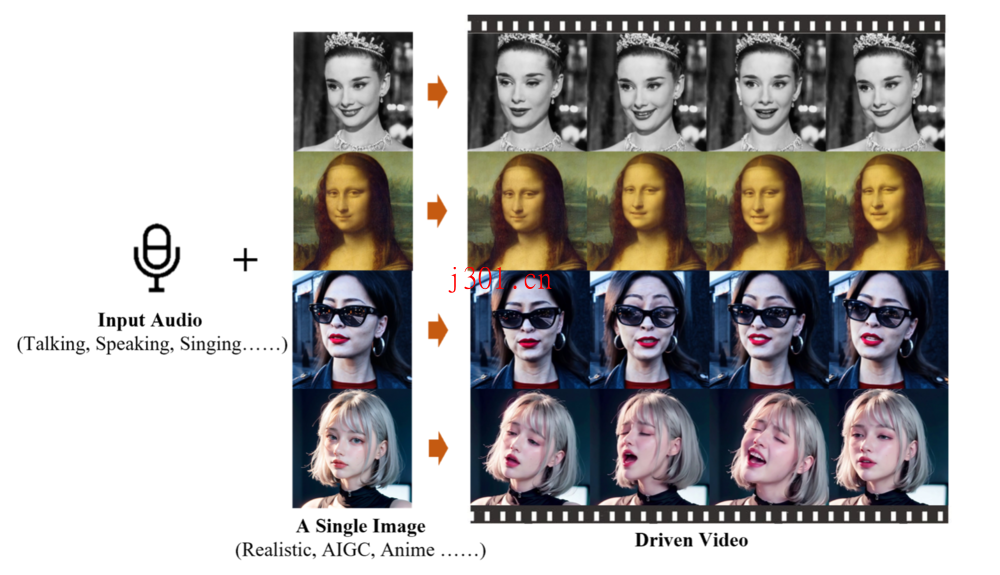
示例
电视剧里的高启强开始给你讲法律,或者是蒙娜丽莎突然唱起了《Perfect》,这画面太美我不敢想。而且阿里说了,不管是什么样的音频、语速、图像,EMO都能搞定,这操作简直了,B站的鬼畜视频估计得升级换代了。


这技术牛在哪儿?
用官方的话说,就是"一种富有表现力的音频驱动的肖像视频生成框架"。简单来说,就是通过声音把照片变成视频,而且还能根据音频的长度随意调整视频时长,想要多长有多长。
技术怎么实现的?
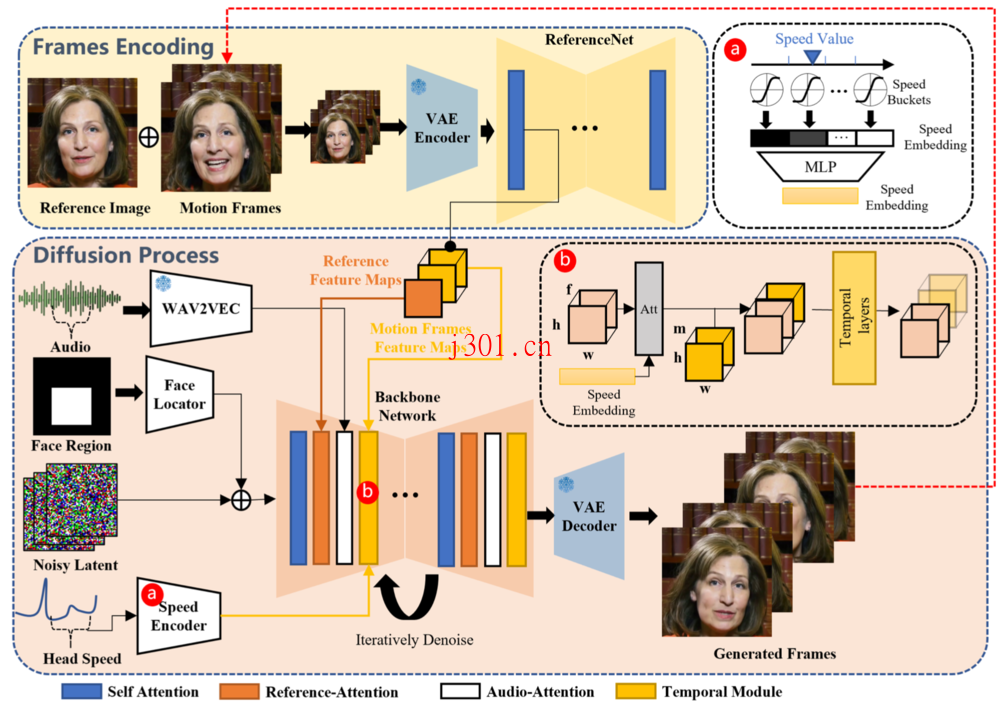
核心是个叫做Audio2Video的扩散模型,大致流程分三步:先从参考图像提取特征,再通过音频编码器处理音频嵌入,最后通过一个主干网络去噪,生成视频。听起来挺复杂的,但结果就是能让照片里的人按照你的音频唱歌跳舞。
相关链接
目前,EMO框架上线到GitHub中,相关论文也在arxiv上公开。
GitHub地址:https://github.com/HumanAIGC/EMO
论文地址:https://arxiv.org/abs/2402.17485
另一方面
但说实话,这技术一方面让人挺激动的,毕竟创造力和娱乐性大大增强了。但另一方面,也挺担心的,特别是对于内容的真实性。以后看视频是不是都得打个问号了?真的假的越来越难分了。
不过,阿里也不是只有这个EMO。之前还推出过Qwen-VL模型,能够处理图像和文本,生成新的内容。看来,阿里在AI这块是下了一番苦工。
最后
这事儿也让人思考,技术发展的同时,我们如何确保它的正向应用,避免滥用呢?毕竟,每项新技术的出现都是双刃剑,如何使用,关键看人。希望未来,我们能更加从容地应对这些挑战,让技术更好地服务于人类。
