


VoiceCraft:在Wild环境中的零样本语音编辑与文本转语音
VoiceCraft如何在Wild环境中实现零样本语音编辑与高效的文本转语音功能。
直达下载
回到上一页 
介绍
VoiceCraft作为一个领先的技术,使零样本语音编辑和文本转语音(TTS)在野外数据上成为可能,如有声书、互联网视频和播客等。这一技术的引入,无疑为语音交互提供了新的维度。
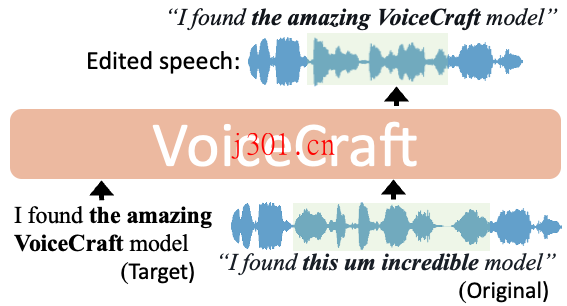
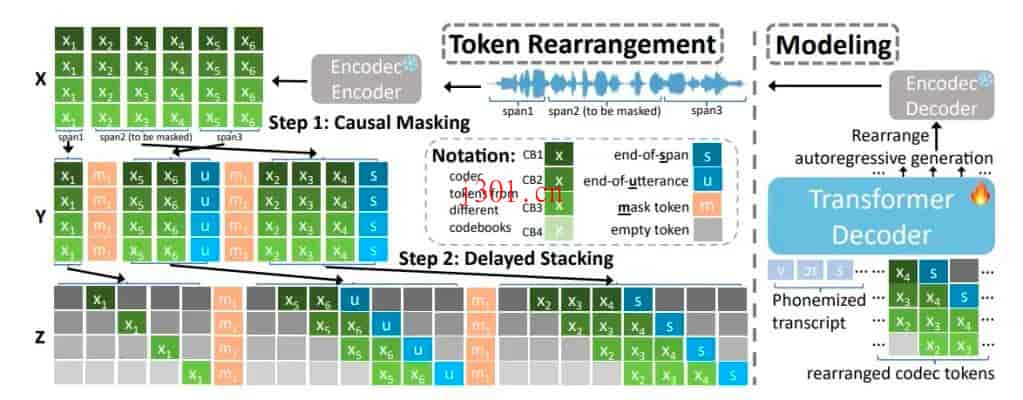
如何运行VoiceCraft
VoiceCraft提供了几种运行方式,用户可以根据需要选择适合的方式来进行语音编辑或TTS推理:
- 在Google Colab中通过Gradio UI运行更灵活的推理。
- 使用Docker进行操作。
- 不使用Docker,在本地运行Gradio。
开发和配置环境
为了使用VoiceCraft进行模型开发,如训练和微调,建议遵循环境设置和训练步骤。此外,你需要设置合适的开发环境,包括安装必要的依赖库和配置Python环境。
conda create -n voicecraft python=3.9.16
conda activate voicecraft
pip install -e git+https://github.com/facebookresearch/audiocraft.git@c5157b5bf14bf83449c17ea1eeb66c19fb4bc7f0#egg=audiocraft
pip install xformers==0.0.22
pip install torchaudio==2.0.2 torch==2.0.1 # this assumes your system is compatible with CUDA 11.7, otherwise checkout https://pytorch.org/get-started/previous-versions/#v201
apt-get install ffmpeg # if you don't already have ffmpeg installed
apt-get install espeak-ng # backend for the phonemizer installed below
pip install tensorboard==2.16.2
pip install phonemizer==3.2.1
pip install datasets==2.16.0
pip install torchmetrics==0.11.1
pip install huggingface_hub==0.22.2
# install MFA for getting forced-alignment, this could take a few minutes
conda install -c conda-forge montreal-forced-aligner=2.2.17 openfst=1.8.2 kaldi=5.5.1068
# install MFA english dictionary and model
mfa model download dictionary english_us_arpa
mfa model download acoustic english_us_arpa
# pip install huggingface_hub
# conda install pocl # above gives an warning for installing pocl, not sure if really need this
# to run ipynb
conda install -n voicecraft ipykernel --no-deps --force-reinstall
如何使用VoiceCraft
运行VoiceCraft时,你可以选择需要的模型,加载模型后进行语音转录。此外,你还可以根据需要调整一些参数,以优化输出的语音效果。
conda activate voicecraft
export CUDA_VISIBLE_DEVICES=0
cd ./data
python phonemize_encodec_encode_hf.py \
--dataset_size xs \
--download_to path/to/store_huggingface_downloads \
--save_dir path/to/store_extracted_codes_and_phonemes \
--encodec_model_path path/to/encodec_model \
--mega_batch_size 120 \
--batch_size 32 \
--max_len 30000
从我个人的使用体验来看,VoiceCraft在操作上的灵活性让我印象深刻。通过简单的设置,我能够在不同的数据上实现精确的语音编辑和TTS,这在以往的技术中是难以想象的。尤其是其零样本语音编辑能力,为我处理多样化的语音数据提供了极大的便利。
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序媛山楂”或者“shanzhacoder” 或微信扫描右侧二维码关注微信公众号
