


MinerU:高质量PDF转Markdown和JSON工具

你有没有遇到过这样的情况:拿到一份PDF文件,想要提取其中的内容,却被复杂的布局和格式搞得焦头烂额?特别是那些科学论文,符号、公式乱七八糟,简直让人崩溃!别急,今天我要给大家介绍一款神器——MinerU,这是一款专注于PDF数据提取的开源工具,能让你轻松把PDF转成Markdown或者JSON格式,简直就是数据处理的好帮手。

MinerU最初是为了支持InternLM的预训练而诞生的,目标是解决科学文献中符号转换的问题。虽然它还很年轻,但功能已经足够强大,特别适合那些需要高质量数据提取的小伙伴。
为什么选择MinerU?
说到PDF数据提取,市面上确实有不少工具,但MinerU的优势就在于它的细致和全面。下面我们来看看它的主要功能吧:
1. 清理杂乱信息,确保语义连贯
MinerU可以自动移除PDF中的页眉、页脚、脚注和页码等干扰信息,让提取的内容更具语义连贯性。再也不用担心提取出来的文本东一句西一句,完全没法读了。
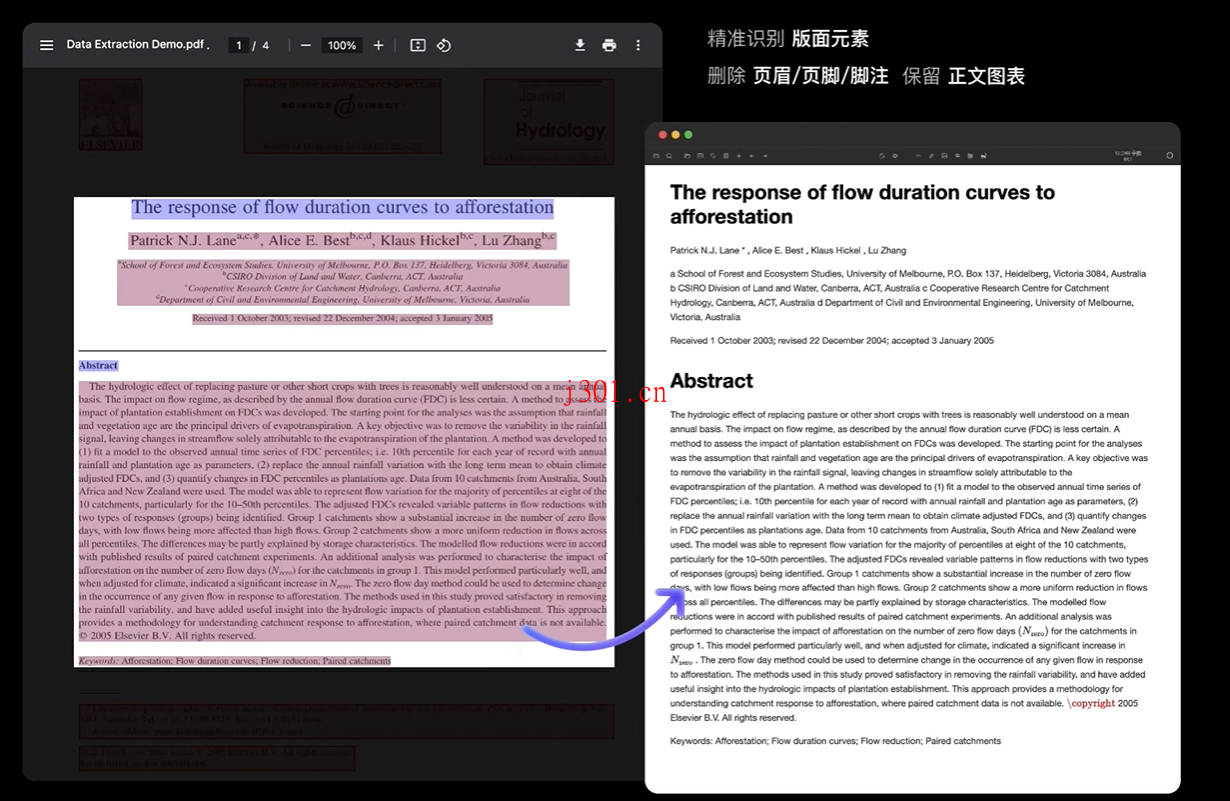
2. 支持复杂布局,轻松还原文档结构
不管是单栏、多栏,还是那些复杂的排版,MinerU都能搞定。而且它还能保留原文档的结构,比如标题、段落、列表等,提取出来的内容看起来就像是“原汁原味”。
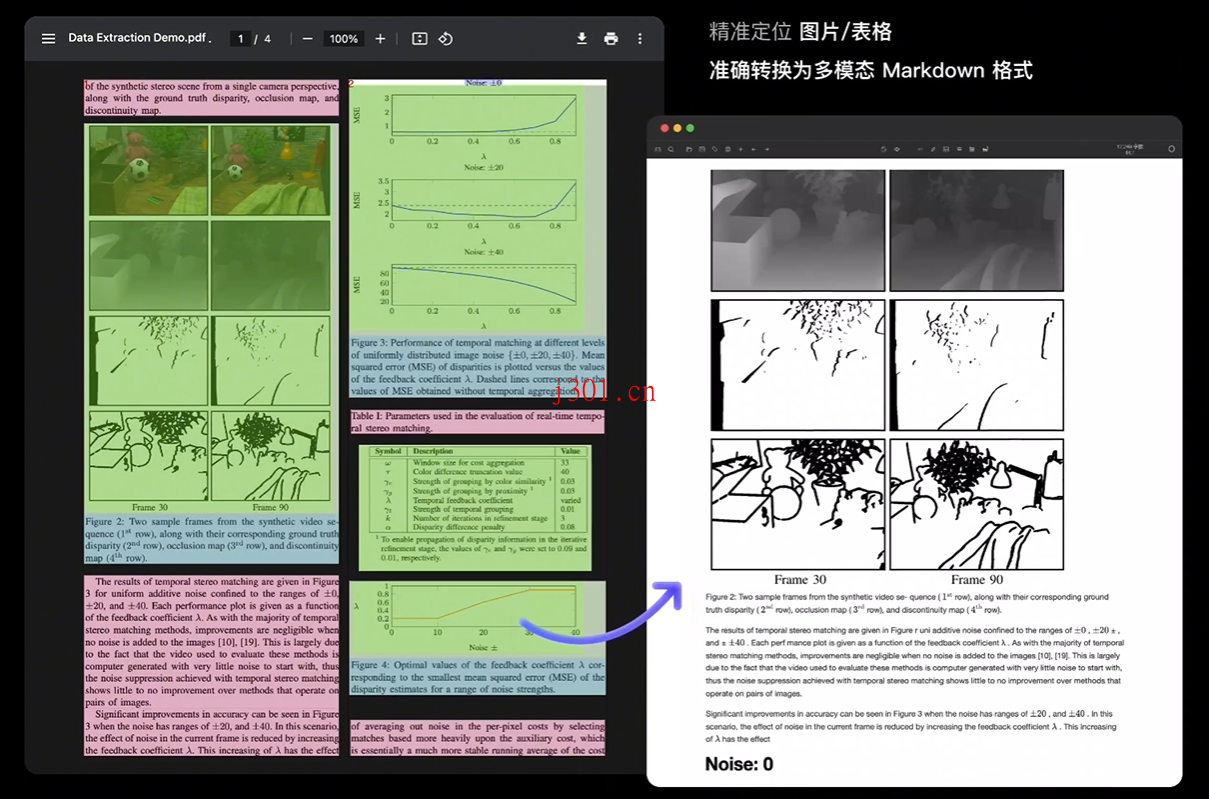
3. 图片和表格?没问题!
如果你的PDF里有图片、图片描述、表格以及表格标题,MinerU也能一并提取出来。尤其是表格,它会自动转换成HTML格式,这样你就可以直接用在网页或者其他地方了。
4. 公式转换,支持LaTeX格式
对于科学文献中的公式,MinerU会自动识别并转换成LaTeX格式,方便你在其他地方继续编辑或者使用。

5. OCR功能,搞定扫描版PDF
遇到扫描版PDF或者乱码PDF?MinerU自带OCR功能,支持84种语言的检测和识别,真的是非常贴心了。
6. 多种输出格式,满足不同需求
不管你是做NLP研究,还是需要多模态数据,MinerU都能满足你的需求。它支持多种输出格式,比如Markdown、按阅读顺序排序的JSON,甚至还有丰富的中间格式供你选择。

7. 可视化检查,确保输出质量
为了让你更方便地确认提取结果,MinerU还支持布局可视化和范围可视化功能。通过这些功能,你可以快速检查输出质量,发现问题并及时调整。
8. 跨平台支持,CPU/GPU都能用
不管你是Windows党、Linux党,还是Mac用户,MinerU都支持。而且它还能在CPU和GPU环境下运行,性能表现相当不错。
MinerU适合谁?
MinerU特别适合那些需要处理大量PDF数据的人,比如:
- 科研人员:需要从论文中提取数据、公式、表格等内容。
- 开发者:需要将PDF内容转化为机器可读的格式,用于后续处理。
- 数据分析师:需要从PDF报告中提取结构化数据。
- 普通用户:想要简单快速地提取PDF内容,不想被复杂的格式折磨。
怎么使用MinerU?
使用MinerU也非常简单,以下是基本的操作步骤:
- 安装MinerU:在GitHub页面下载适合自己系统的版本,按照文档进行安装。
- 准备PDF文件:将需要提取的PDF文件放到指定目录。
- 运行MinerU:通过命令行或者脚本运行MinerU,选择需要的输出格式,比如Markdown或者JSON。
- 检查结果:利用MinerU的可视化功能,检查提取结果是否符合预期。如果有问题,可以调整参数或者提交issue寻求帮助。
用下来,MinerU真的让我省了不少事儿,特别是那些复杂的PDF文档,提取起来又快又准。如果你也经常需要处理PDF数据,那一定要试试这个工具。虽然它还有成长空间,但已经足够强大,完全可以替代一些商业工具。最重要的是,它是开源的,完全免费!

反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序媛山楂”或者“shanzhacoder” 或微信扫描右侧二维码关注微信公众号
